

山脇 弘成(SSAITS代表)
PMP®有資格者・Webプロジェクトマネージャー。
大手メディアや官公庁のWebプロジェクト実績多数。
「技術」だけでなく「対話」を重視し、御社の「ほんとは、こうしたかった」を形にします。
正規化の概要
データベースの正規化(normalization)とは、データベースに保存されているデータを使用しやすくするために、ルールに基づいて整理・変形することをいいます。
正規化を行うことで、データの追加・更新・削除に伴う不整合や喪失が起きるのを防ぐことができ、メンテナンスの効率性を高めていくことができます。
正規化を正しく行っておけば、データベース運用時に発生する問題を未然に防止することができます。そのため、運営コストを削減するためにも正規化の必要性が謳われているのです。
この正規化というアイデアはソフトウェア開発をしていると前提知識として扱われることが多く、基本情報技術者試験・応用情報技術者試験などの情報処理技術者試験にも頻出の問題です。
そのため、正規化は新人のSEさんやテクニカルディレクターさんは押さえておきたい用語です。
今回はこのデータベースの正規化を新人SEやテクニカルディレクターに向けて解説していきます。
正規化のメリットを理解し、ゴールを明確にする
正規化の手順をお話しする前に、正規化のメリットを理解し、「どうすれば正規化ができたといえるのか」を明らかにしていきましょう。
非正規なデータの状態
まずは正規化されていないデータ、つまり非正規なデータがどのようなものなのかを見ていきましょう。
正規化されていないテーブルは、その中に繰り返しの項目が存在しています。
・表1:正規化されていないテーブル
| 受注No. | 受注日 | 顧客名 | 顧客No. | 商品名 | 商品コード | 単価 | 数量 | 商品名 | 商品コード | 単価 | 数量 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 2020/11/11 | A社 | D001 | ペン | A100 | 100 | 12 | 消しゴム | A100 | 80 | 10 |
| 11 | 2020/11/20 | B社 | D002 | 消しゴム | B100 | 80 | 10 | 消しゴム | B100 | 80 | 10 |
| 12 | 2020/11/25 | C社 | D003 | ペン | A100 | 100 | 20 | ペン | C100 | 100 | 10 |
上の表1は、よくありがちな取引をまとめたテーブルです。
受注の管理番号があり、その顧客名、顧客番号があり、その後には商品名、商品コード、単価、数量の4つの項目が繰り返しになっています。
なぜこのようなテーブルができてしまったかというと、「商品コードだけじゃわかりにくいから商品名をいれてみた」「売れたデータをどんどん入力できるように、商品名から数量までが繰り返されるようにした」など、様々な理由がありそうです。
補足)テーブルとは何か?
ソフトウェア開発のデータベースというと新人の方にとっては難しく感じてしまいますが、表1のようにExcelで作った表組のようなものを機械が覚えており、適宜その情報を出力していると考えていれば、ひとまず問題はありません。
こうしたデータの表組のことをテーブルと呼びます。
正規化されていないが故のトラブル
表1のテーブルは少し見ただけでも、このテーブルが使いにくいものだと感じるかと思います。
例えば、「商品名が変更になった時に1つ1つデータを直していくのか」「1社から複数の注文があった場合、このテーブルは右に長くなっていくのか」というような疑問が浮かぶでしょう。
また、売上の合計がデータベース上のデータと実データでは合わないという場合に、表1のようなテーブルから間違いを探すのは至難の業です。
このように、正規化されていないテーブルというのは管理しづらくなるだけでなく、何かトラブルがあった際に対応しづらくなります。
また表1のようにごちゃごちゃとしたつくりのテーブルは、テーブルからデータを1行追加・削除しただけで、エラーが発生してしまうこともあります。
無用なトラブルを回避するためにも、正規化を行い、管理しやすく、エラーの発生しないテーブルの構造を目指していく必要があります。
正規化の方法
データベースのデータを整理・変形していく正規化の段階は次のように分けられています。
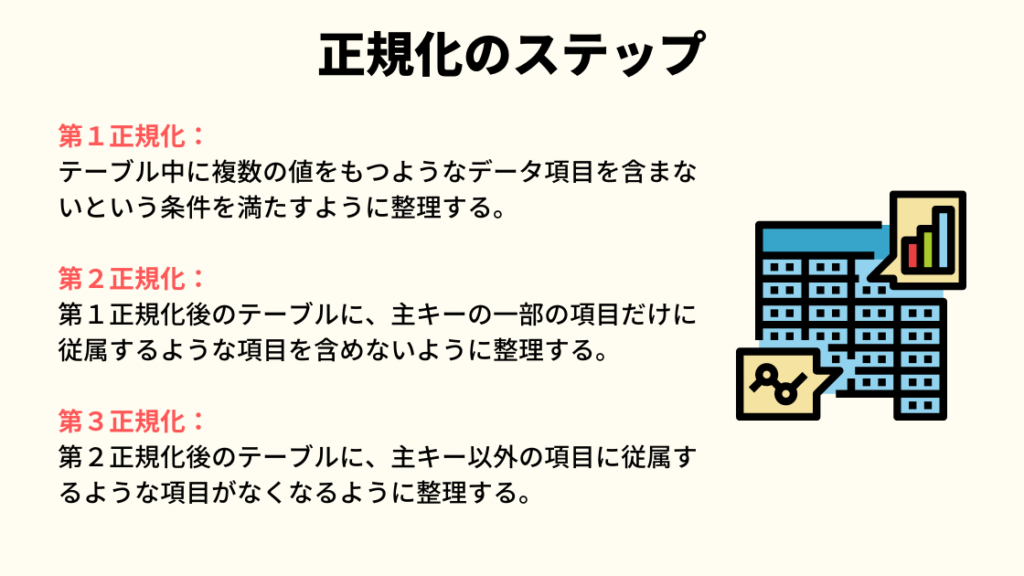
- 第1正規化
:テーブル中に複数の値をもつようなデータ項目を含まないという条件を満たすように整理する。 - 第2正規化
:第1正規化後のテーブルに、主キーの一部の項目だけに従属するような項目を含めないように整理する。 - 第3正規化
:第2正規化後のテーブルに、主キー以外の項目に従属するような項目がなくなるように整理する。
この正規化は第3正規化の状態まで対応することが多く、第2正規化でストップするということはあまりありません(意図せず途中になっているということはありますが……)。
そのためここからは、第3正規化までの手順を解説していきます。
第1正規化
繰り返しの項目が存在する非正規形から、繰り返し部分を取り除いていきます。
非正規形の表の横方向に伸びた繰り返し部分を切り離して、重複をなくしていくのが第1正規化です。
例えば、先ほどの表1のテーブルの商品名から数量までの項目の繰り返しを切り離した形は以下のようになります。
・表2-1
| 受注No. | 受注日 | 顧客名 | 顧客No. |
|---|---|---|---|
| 10 | 2020/11/11 | A社 | D001 |
| 11 | 2020/11/20 | B社 | D002 |
| 12 | 2020/11/25 | C社 | D003 |
・表2-2
| 受注No. | 商品名 | 商品コード | 単価 | 数量 |
|---|---|---|---|---|
| 10 | ペン | A100 | 100 | 12 |
| 10 | 消しゴム | B100 | 80 | 10 |
| 11 | 消しゴム | B100 | 80 | 10 |
| 11 | 消しゴム | B100 | 80 | 10 |
| 12 | ペン | A100 | 100 | 20 |
| 12 | ペン | A100 | 100 | 10 |
ここでは、表1の乱雑なテーブルを受注No.と顧客の情報がまとめられた表2-1と各注文でどのような商品がどの程度購入されたのかを示す表2-2に分けています。
この第1正規化が完了したテーブルを「第1正規形」と呼びます。繰り返しの部分が別になっただけでも、テーブルが見やすくなり、情報の管理しやすいものになったことが感じられるかと思います。
しかし、より管理をしやすくするために、まだまだテーブルに手を加えていける部分がありそうです。
第2正規化
データをより管理しやすくするために、第1正規形のテーブルで主キーの一部だけに従属している部分を分離します。この方法を第2正規化といいます。
表2-2を第2正規化し、第2正規形のテーブルにしたものは以下のようになります。
・表3-1
| 受注No. | 商品コード | 数量 |
|---|---|---|
| 10 | A100 | 12 |
| 10 | B100 | 10 |
| 11 | B100 | 10 |
| 11 | B100 | 10 |
| 12 | A100 | 20 |
| 12 | A100 | 10 |
・表3-2
| 商品コード | 商品名 | 単価 |
|---|---|---|
| A100 | ペン | 100 |
| B100 | 消しゴム | 80 |
補足)主キーとは何か?
主キーとは、wikiでは以下のように説明されています[1] 主キー – Wikipedia 。
関係に格納されたレコードを一意に識別するための属性(列、アトリビュート)またはその集合のうち、そのために通常利用されるべき特定の一つをいう。
しかし、この説明も難しいため、慣れない内は「データを特定するために使われる鍵となるデータ」としてしまってもよいかもしれません。
例えば、表2-1は受注No.がわかっていれば、いつ注文されたか(受注日)、顧客、顧客No.がわかります。
一方、表2-2では受注No.と商品コード(あるいは商品名)がわかっていなければ、数量が明らかになりません。
このように、表2-2は受注No.と商品コードの2つが主キーであるといえますが、商品コードがわかれば明らかになるような商品名や単価があります。これを分離するのが第2正規化です。
補足)非キーとは何か?
正規化の中では「主キー」とともに、「非キー」という言葉もでてきます。
これは先ほどの表2-2の数量のようなもので、数量の値がわかっても、受注No.や商品コードを割り出すことはできません。
このように、この項目が決まったとしても、他の部分が明らかにならないような項目を非キーと呼びます。
難しく考えず、主キー以外の項目と置き換えてしまっても、試験に取り組む程度であれば問題ありません。
第3正規化
第2正規形でデータの冗長性を取り除くことができました。しかし、まだ改良の余地はあります。
例えば、顧客の会社名が変わった際に、表2-1のように顧客No.と顧客名をすべての注文に記入していた場合は、いちいちすべての会社名を変えていかなければなりません。
これは面倒である上に、ヒューマンエラーで修正漏れなどがでてしまうかもしれません。
この顧客名は主キーである受注No.がわからずとも、顧客コードさえわかっていれば特定できる情報です。そのため、表2-1から顧客名を以下のように分離させていきます。
・表4-1
| 受注No. | 受注日 | 顧客No. |
|---|---|---|
| 10 | 2020/11/11 | D001 |
| 11 | 2020/11/20 | D002 |
| 12 | 2020/11/25 | D003 |
・表4-2
| 顧客No. | 顧客名 |
|---|---|
| D001 | A社 |
| D002 | B社 |
| D003 | C社 |
このような場合も管理しやすいように、主キー以外の項目同士の依存関係も切り分けていきます。
最終的なテーブルの姿
ここまでで第3正規化までが完了いたしました。
最終的に表1のテーブルは以下のようなテーブルに整理されました。
| 受注No. | 受注日 | 顧客No. |
|---|---|---|
| 10 | 2020/11/11 | D001 |
| 11 | 2020/11/20 | D002 |
| 12 | 2020/11/25 | D003 |
| 受注No. | 商品コード | 数量 |
|---|---|---|
| 10 | A100 | 12 |
| 10 | B100 | 10 |
| 11 | B100 | 10 |
| 11 | B100 | 10 |
| 12 | A100 | 20 |
| 12 | A100 | 10 |
| 商品コード | 商品名 | 単価 |
|---|---|---|
| A100 | ペン | 100 |
| B100 | 消しゴム | 80 |
| 顧客No. | 顧客名 |
|---|---|
| D001 | A社 |
| D002 | B社 |
| D003 | C社 |
このように、第3正規化まで終えたテーブルは、冗長性が排除され、データの整合性を保ちやすくなります。
応用情報技術者試験での出題
応用情報技術者試験でも正規化は頻出の問題です。
例えば以下のような形式でも出題されています。
第1、第2、第3正規形とそれらの特徴a~cの組合せのうち、適切なものはどれか。
応用情報技術者試験 平成30年度秋午前問28
a:どの非キー属性も、主キーの真部分集合に対して関数従属しない。
b:どの非キー属性も、主キーに推移的に関数従属しない。
c:繰り返し属性が存在しない。
第1正規形 第2正規形 第3正規形 ア a b c イ a c b ウ c a b エ c b a
先ほどの問題の中で、第1正規形がどれかはすぐにわかるかと思います。
第1正規化は繰り返しになっている部分を切り離して整理することでしたから、「c:繰返し属性が存在しない。」が該当します。つまり、第1正規形にはcが入ります。
しかし、a・bには「真部分集合」や「関数従属」という見慣れぬ用語が含まれています。これらの用語を見ていきながら、もう少し正規化の理解を深めていきましょう。
真部分集合
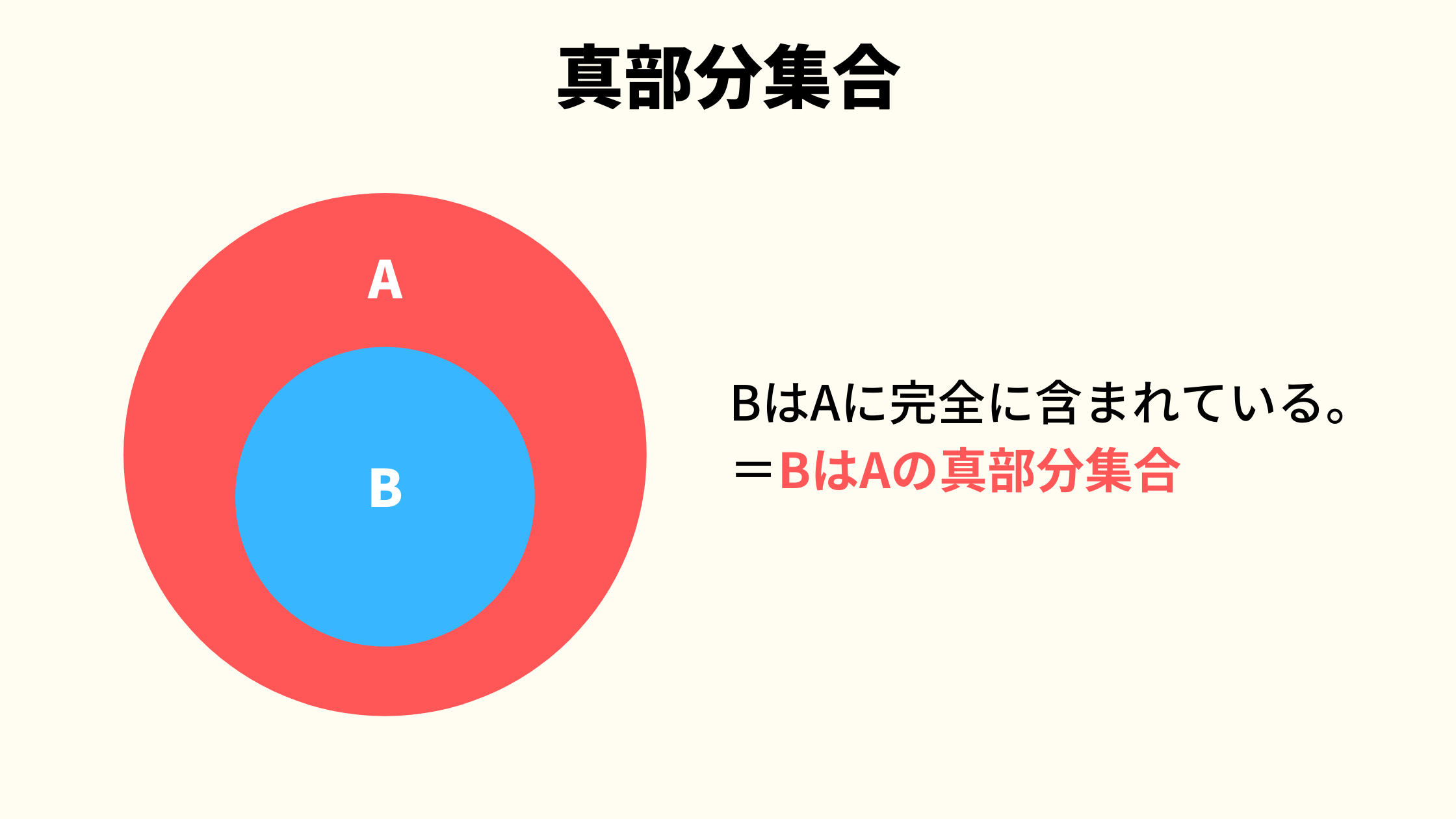
真部分集合とは、ある集合が別の集合に完全に含まれている状態をいいます。
参考画像1のように、集合Bは集合Aに完全に含まれており、まったくはみ出していません。
こういう状態を真部分集合といいます。
例えば、「ヒト」は「動物」という集合に属していますが、こうした集まりをいいます。
では、先ほどの応用情報技術者試験の「a:どの非キー属性も、主キーの真部分集合に対して関数従属しない。」とはどういうことでしょうか?
「主キーの真部分集合」という言葉を言いかえると、「主キーに完全に属している集合」ということになります。
つまり、「主キーの一部に属しているような項目」をどうのこうのするということを言っているので、この時点で第2正規化の話をしている可能性が極めて高いのですが、後に続く「関数従属」についても念のため見ていきましょう。
関数従属とは?
関数従属とは、ある項目が決定すると、自動的に別の項目の値も決まるような関係にあることです。
つまり、「この項目の値がわかれば、この項目の値が導き出せる」というような関係を関数従属といいます。
つまり、aの内容は「主キーの一部がわかれば、判明するような項目がない」状態にすることを言っているので、やはり第2正規化(第2正規形)の話をしていたということがわかります。
推移的関数従属とは?
先ほどの問題を解くだけなら、第1正規形がcとわかり、第2正規形がaであるということがわかったので、答えが選択肢ウであることが導き出せます。
しかし、ここはもう少し踏み込んで、「b:どの非キー属性も、主キーに推移的に関数従属しない。」という問題文に出てきた「推移的に関数従属」という言葉を解説していきます。
この推移的関数従属というのは、「AがわかればBがわかり、BがわかればCがわかる」というような関係のことです。
例えば、表2-1から顧客名と顧客No.の部分を切り分けましたが、これは受注No.がわかれば、顧客No.がわかり、顧客No.が判明すれば、自動的に顧客名が明らかになるからでした。
このような関係にある項目を切り出したのが第3正規化でしたので、 「b:どの非キー属性も、主キーに推移的に関数従属しない。」 というのが第3正規化(第3正規形)のことを意味していることがわかります。
注