
カオスエンジニアリング(Chaos Engineering)とは、一言で言えば「システムがあえて壊れるような状況を作り出し、それに耐えられるかを実験する手法」のことです。
分散システム(マイクロサービスなど)は複雑で、いつどこで障害が起きるか予測困難です。
そこで、障害が起きてから慌てて対処するのではなく、意図的に障害(カオス)を注入してシステムの弱点を見つけ、事前に修正することで、システム全体の「回復力(レジリエンス)」を高めることを目的とします。
今回は、このカオスエンジニアリングについて解説し、応用情報技術者試験での例題を紹介していきます。

山脇 弘成(SSAITS代表)
PMP®有資格者・Webプロジェクトマネージャー。
大手メディアや官公庁のWebプロジェクト実績多数。
「技術」だけでなく「対話」を重視し、御社の「ほんとは、こうしたかった」を形にします。
カオスエンジニアリングはなぜ必要なのか?
カオスエンジニアリングが求められる理由は大きく分けて3つあります。
「未知の未知(Unknown Unknowns)」を発見するため
従来のテスト(単体テストや結合テスト)は、「ここでエラーが起きるかもしれない」と人間が予測できる範囲(既知の事象)しか確認できません。
しかし、現代の複雑なシステムでは、開発者が想像すらしていない場所や組み合わせで障害が起きます。
- 例:Aサービスが遅延したせいで、全く関係ないはずのBサービスのデータベース接続がタイムアウトし、結果としてC機能が全停止する。
こうした「実際に起きてみないと分からない弱点(未知の未知)」を、ユーザーが踏む前に、意図的な障害によってあぶり出すために必要です。
本番環境と開発環境の「決定的違い」を埋めるため
「開発環境では完璧に動いていたのに、リリースしたら動かない」という経験はエンジニアなら誰しもあるはずです。それはなぜでしょうか?
- ネットワークのゆらぎ: 本番環境のネットワークは、物理的な距離や混雑状況によって常に不安定です。
- トラフィックの予測不能さ: ユーザーのアクセス集中はシミュレーションしきれません。
- 設定の微妙なズレ: 本番環境だけロードバランサの設定が古い、など。
「本番環境こそが唯一の真実」であるため、きれいな箱庭(開発環境)ではなく、泥臭い現実世界(本番環境)でテストする必要があります。
「MTBF(平均故障間隔)」から「MTTR(平均復旧時間)」へのパラダイムシフト
昔の汎用機のようなシステムは「絶対に壊れないこと(堅牢性)」を目指していました。しかし、クラウドやマイクロサービスが主流の現代において、「システムは絶対にいつか壊れる」という前提に立っています。
- 旧来の考え: 障害を起こさないように祈る(MTBFを長くする)。
- カオスエンジニアリングの考え: 障害は起きるものとし、起きてもすぐに自動回復できるようにする(MTTRを短くする)。
「障害が起きてもサービスが止まらない(あるいは瞬時に直る)」という免疫(レジリエンス)をつけるためには、普段から小さいウイルス(障害)を注入して訓練しておく必要があります。
システムにおけるワクチンの役割を担うのがカオスエンジニアリングです。
カオスエンジニアリングの「5つの原則」
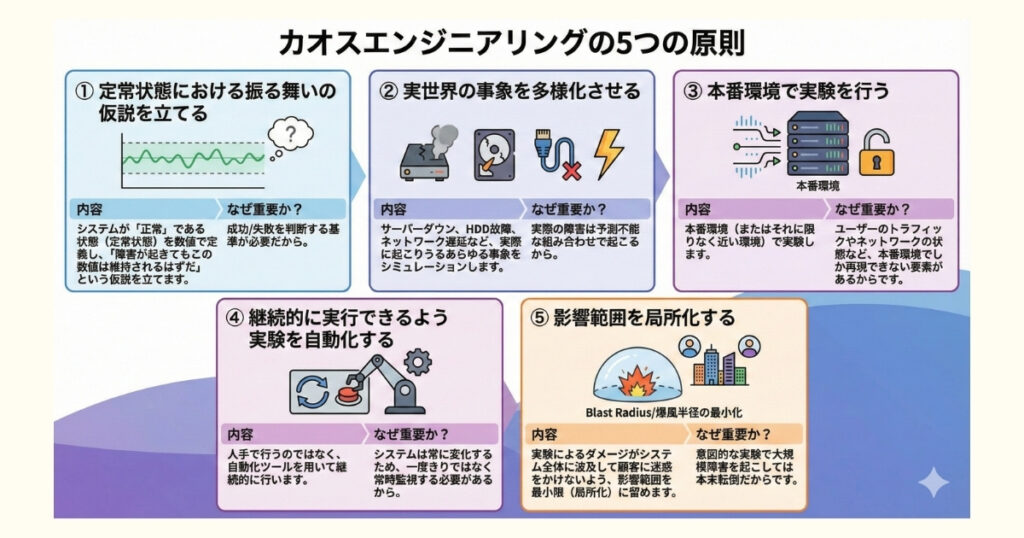
カオスエンジニアリングには、提唱されている「5つの原則(Principles of Chaos Engineering)」があります。
応用情報技術者試験などの情報技術者試験ではこの「5つの原則」の理解が問われます。
| 原則 | 内容 | なぜ重要か? |
| ① 定常状態における振る舞いの仮説を立てる | システムが「正常」である状態(定常状態)を数値で定義し、「障害が起きてもこの数値は維持されるはずだ」という仮説を立てます。 | 成功/失敗を判断する基準が必要だから。 |
| ② 実世界の事象を多様化させる | サーバーダウン、HDD故障、ネットワーク遅延など、実際に起こりうるあらゆる事象をシミュレーションします。 | 実際の障害は予測不能な組み合わせで起こるから。 |
| ③ 本番環境で実験を行う | 本番環境(またはそれに限りなく近い環境)で実験します。 | ユーザーのトラフィックやネットワークの状態など、本番環境でしか再現できない要素があるからです。 |
| ④ 継続的に実行できるよう実験を自動化する | 人手で行うのではなく、自動化ツールを用いて継続的に行います。 | システムは常に変化するため、一度きりではなく常時監視する必要があるから。 |
| ⑤ 影響範囲を局所化する | 実験によるダメージがシステム全体に波及して顧客に迷惑をかけないよう、影響範囲を最小限(局所化)に留めます。 | 意図的な実験で大規模障害を起こしては本末転倒だからです(Blast Radius/爆風半径の最小化とも呼ばれます)。 |
過去問に挑戦!
それでは、実際の試験問題で理解度を確認しましょう。
令和7年度 応用情報技術者試験 春期 午前 問49
分散システムの脆弱性を実験によって発見する手法であるカオスエンジニアリングには,五つの原則がある。この原則のうちの三つは,”定常状態における振る舞いの仮説を立てる”,”実世界の事象を多様化させる”,”継続的に実行できるよう実験を自動化する”である。あと二つの原則の組はどれか。
ア “開発環境で実験を行う”,”影響範囲を局所化する”イ “開発環境で実験を行う”,”影響範囲を広く捉える”
ウ “本番環境で実験を行う”,”影響範囲を局所化する”
エ “本番環境で実験を行う”,”影響範囲を広く捉える”
解説
この問題の正解は ウ です。
カオスエンジニアリングの「5つの原則」のうち、問題文で挙げられていない残りの2つは、「本番環境で実験を行う」と「影響範囲を局所化する」です。
この点をおさらいしておきましょう。
なぜ「本番環境」なのか?
従来のテストのように開発環境で行うだけでは、実際のユーザーの動きや、複雑なネットワークの遅延などを完全に再現することはできません。「本番環境でしか起こり得ない不確実性」を検証してこそ、真の堅牢性を確認できるというのがカオスエンジニアリングの核心です。
なぜ「局所化」なのか?
「本番環境で壊す」といっても、サービス全体を止めてしまっては本末転倒です。特定のユーザー層だけに限定したり、特定のサーバー群だけに障害を注入したりすることで、万が一の際の「爆風半径(Blast Radius)」を最小限に抑える設計が不可欠です。
まとめ:障害を「防ぐ」から「飼い慣らす」へ
今回は、複雑なシステムを安定稼働させるための攻めの手法「カオスエンジニアリング」について解説しました。
- カオスエンジニアリングは、意図的に障害を起こしてシステムの弱点を見つける手法。
- 目的は「絶対に壊れないシステム」を作ることではなく、「壊れてもすぐに立ち直る力(レジリエンス)」を鍛えること。
- 試験対策としては、「5つの原則」(特に本番環境での実行と影響範囲の局所化)を確実に押さえておくこと。
クラウドネイティブな開発が当たり前となった現代、エンジニアには「障害は必ず起きるもの」という前提でシステムを設計・運用するマインドセットが求められています。
試験合格はもちろん、実務においても「あえて壊してみることで得られる安心感」というカオスエンジニアリングの考え方を取り入れてみてはいかがでしょうか。