
最新のAIツール「NotebookLM」を使って、手持ちのPDF資料を読み込ませようとしたらエラーになってしまった…そんな経験はありませんか?
今回は、NotebookLMでPDFが読み取れなくて困っている初心者の方に向けて、エラーの原因と「OCR処理」という簡単な解決策をご紹介します。完全無料でできる裏技も解説するので、ぜひ最後までご覧ください!

山脇 弘成(SSAITS代表)
PMP®有資格者・Webプロジェクトマネージャー。
大手メディアや官公庁のWebプロジェクト実績多数。
「技術」だけでなく「対話」を重視し、御社の「ほんとは、こうしたかった」を形にします。
NotebookLMでPDFが読み込めない!?
先日、仕事や読書のリサーチのために、本や紙の資料をスキャンしたPDFファイルをNotebookLMにアップロードしてみました。しかし結果はエラー。
何度PDFをアップロードしても、エラーが表示され、PDFを読み込んでもらえませんでした。
文字はしっかり見えているのになぜ?と疑問に思いましたが、実はこれ、「紙をスキャンしただけ」のPDF特有の落とし穴でした。
原因は「OCR処理」がされていないこと
結論から言うと、エラーの原因はPDFファイルにOCR処理が施されていなかったためです。
OCR処理とは?
OCR(Optical Character Recognition:光学式文字認識)とは、画像の中にある文字を見つけ出し、コンピュータが理解できる「テキストデータ」に変換する技術のことです。
私たちがスキャナーやスマホで紙を取り込んだ直後のPDFは、人間には文字が見えていても、コンピュータにとってはただの「写真(画像データ)」の集まりにすぎません。
NotebookLMはテキストデータを読み込んで情報を整理するAIなので、写真の中に閉じ込められた文字を直接読むことはできないのです。
そこで、画像化された文字をなぞって本物のテキストデータに変換する「OCR処理」が必要になります。
OCR処理を行う4つの方法(おすすめ順!)
原因がわかれば対処は簡単です。ご自身の環境や目的に合わせて、以下の方法を試してみてください。
おすすめ度1位:Adobe Acrobat Proを使う(確実・レイアウト維持)
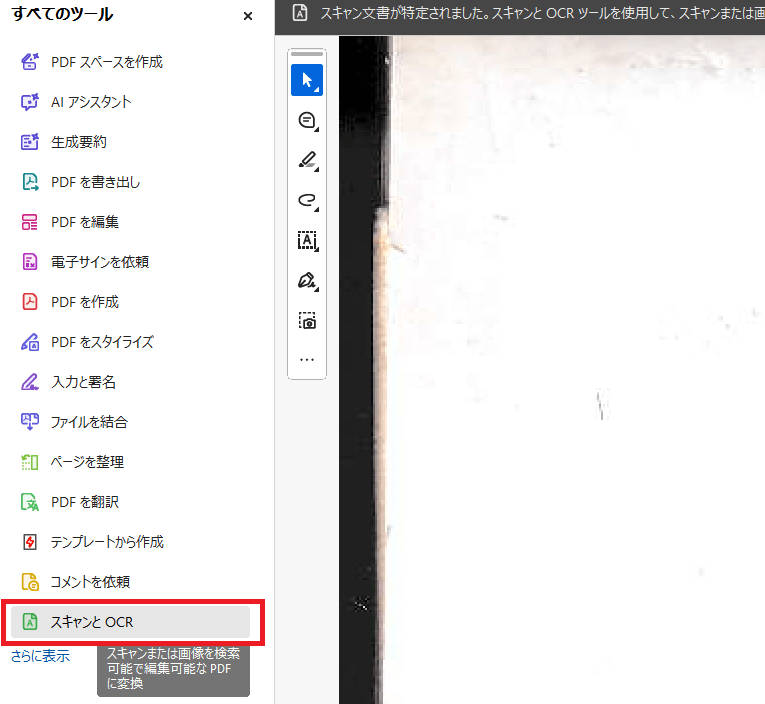
最も確実で、PDFの見た目を崩さずにテキストだけを埋め込めるのがPDF編集ソフトの定番「Adobe Acrobat Pro」を使う方法です。ソフトをお持ちの方にはこちらを一番おすすめします。
- Acrobat Proで該当のPDFファイルを開く。
- ツールメニューから「スキャンとOCR」を選択する。
- 「テキスト認識」を実行して保存する。
おすすめ度2位:Google ドライブを活用する(完全無料の裏技)
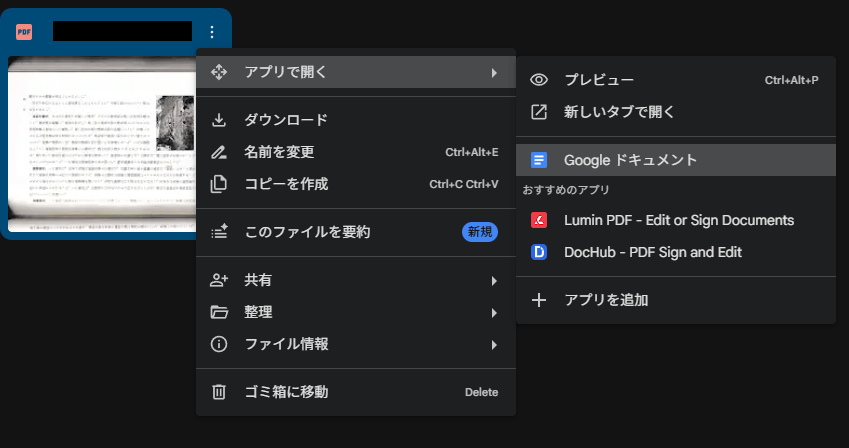
Acrobatなどの有料ソフトを持っていない方におすすめなのが、Google ドライブを使った無料の裏技です。PDFのレイアウトは崩れますが、NotebookLMにテキストを読み込ませる目的であればこれで十分です。
- スキャンしたPDFをGoogle ドライブにアップロードする。
- ドライブ上でファイルを右クリック(またはメニューを開く)し、「アプリで開く」>「Google ドキュメント」を選択する。
- 自動的に画像から文字が抽出され、テキストデータに変換されたドキュメントが作成される。
- このドキュメントを直接NotebookLMに読み込ませる。
おすすめ度3位:スマホのスキャンアプリを使う(これからスキャンする人向け)
もし、これから紙の資料をスキャンするのであれば、初めからOCR機能がついたアプリを使うのが最もスムーズです。例えば無料アプリの「Adobe Scan」などは、スキャンして保存する際に自動でテキストを認識し、文字データ付きのPDFを作成してくれます。
おすすめ度4位:オンラインの無料ツールを使う
「Adobe Acrobat オンラインツール」や「iLovePDF」などの無料ウェブサービスでも、PDFをアップロードするだけでOCR変換が可能です。(※ただし、機密情報や個人情報が含まれる文書での利用は避けるのが無難です)
再度読み込ませると見事に成功!
OCR処理を完了させたファイルを、改めてNotebookLMに共有してみました。
結果は……大成功!
今度はエラーになることもなく、資料の隅々まで正確に読み取ってくれました。目的の章をピンポイントで要約させたり、知りたい情報を抽出したりと、NotebookLMの強力な機能をフル活用できるようになりました。
まとめ
- スキャンしただけのPDFは画像データなのでNotebookLMで読み込めない。
- 解決するには、画像をテキストデータに変換する「OCR処理」が必要。
- Acrobat Proなら確実。無料で済ませるならGoogle ドライブ経由がおすすめ!
NotebookLMにPDFをアップロードしてエラーが出た時は、まず「そのPDFの文字はマウスで選択・コピーできるか(テキストデータになっているか)」を確認してみてください。OCR処理を活用して、快適なリサーチライフを送りましょう!